【ai全栈】目标检测算法总结
目标检测综述
目标检测就是求解图像中的目标框如猫:(x, y, w, h)。
如果按照分类的思路去做目标检测,即建立一个卷积神经网络+全联接层来从图像中取不同的感兴趣区域RoI来分类,但是这种做法并不高效,所以才有了R-CNN,YOLO等算法来高效的解决这类问题。
R-CNN
为了避免在图像中选择大量的Regions,Ross Girshick et al.提出了一种方法,这种方法使用selective search只需要从图像中提取2000个区域,称作region proposals。selective search算法的原理如下:
1. 生成初始的sub-segementation,生成了许多候选的region
2. 使用贪心算法递归的合并小区域为大区域
3. 使用生成的区域来生产最终的候选region proposals

提取的2000个region proposals被送进CNN网络得到4096维的特征向量输出,最终送到SVM分类器确认其中是否有某一类目标。对于目标检测,光有分类器还不够,网络最后还要送入一个Bbox reg模块,来预测bounding box的四个偏移量,以精准的得到目标的范围。

selective search算法尽管一定程度上降低了计算量,但是在提取region proposals的过程中没有训练参与,所以得到的候选rp不一定好。
Fast R-CNN
相比R-CNN要把2000个rp送进CNN分别进行卷积耗费时间,Fast R-CNN只需要将图片送进CNN做一次卷积,然后从得到的特征映射中识别rp,然后接roi pooling将目标框对应特征图resize到相同的尺度以满足全连接层固定尺寸的输入制约,接两层全连接层后分别进行目标的softmax分类和基于回归的目标框偏移预测。
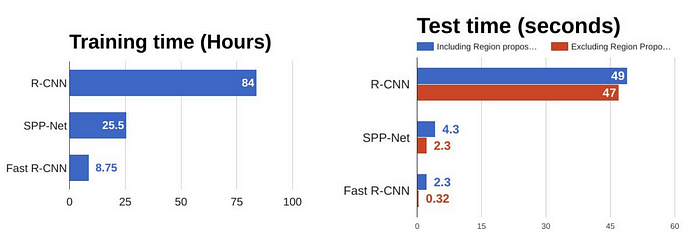
Fast R-CNN无论是训练还是测试都要比R-CNN快的多,然而(右图可见)region proposals依然是制约Fast R-CNN的test环节速度的瓶颈。
RoI Pooling的计算原理可以参考以下动图RoI Pooling,分析之前先来看看RoI Pooling Layer的caffe prototxt的定义:
layer {
name: "roi_pool5"
type: "ROIPooling"
bottom: "conv5_3"
bottom: "rois"
top: "pool5"
roi_pooling_param {
pooled_w: 7
pooled_h: 7
spatial_scale: 0.0625 # 1/16
}
}
其中有新参数pooled_w和pooled_h,另外一个参数spatial_scale认真阅读的读者肯定已经知道知道用途。RoI Pooling layer forward过程:
1. 由于proposal是对应MxN尺度的,所以首先使用spatial_scale参数将其映射回(M/16)x(N/16)大小的feature map尺度;
2. 再将每个proposal对应的feature map区域水平分为[pooled_w x pooled_h]的网格;
3. 对网格的每一份都进行max pooling处理。
这样处理后,即使大小不同的proposal输出结果都是pooled_w x pooled_h固定大小,实现了固定长度输出。
Faster R-CNN
R-CNN & Fast R-CNN通过selective search算法来寻找region proposals时间效率太低,Shaoqing Ren et al.摈弃了selective search算法,让网络去学习region proposals,这个独立的网络叫区域候选网络region proposals network(rpn)。
相比Fast R-CNN对cnn提取的feature map施加selective search算法生成rp,Faster R-CNN接rpn网络生成rp,之后的操作和Fast R-CNN无太大差别。
RPN网络用于生成region proposals,原理如下:
1. Conv layers计算获得的feature maps,为每一个点都配备不同尺度的9种anchors作为初始的检测框;
2. 通过softmax判断anchors属于positive或者negative,按照正负比例1:3保留anchors;
3. 再利用bounding box regression修正anchors获得精确的proposals;
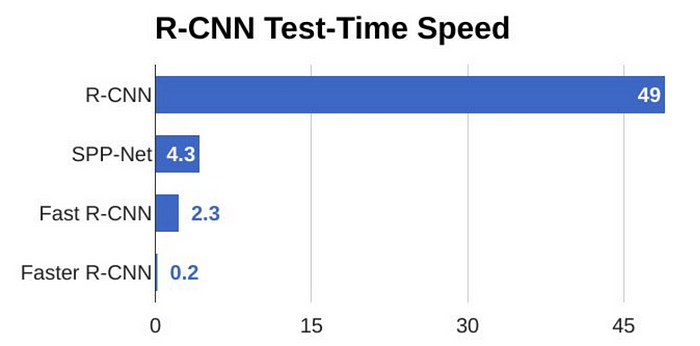
Faster R-CNN模型一幅图0.2s的检测速度已经可以作为一个实时检测算法使用了:
Mask R-CNN
何凯明大神所言,实例分割有两种思路,一是segmentation-first,二是instance-first,Mask R-CNN是后者
RoI Pooling的缺陷和RoIAlign的引入: 分块池化导致RoI和Feaure Map错位(misalignments),这对分类来说带来误差可以忽略不记,但是对于逐像素的分割掩膜来说影响就大了。
Mask-RCNN: 目标检测用了faster r-cnn,特征提取用了特征金字塔网络fpn
实验提升tricks:
- 端到端训练相比先训练RPN再训练Mask R-CNN会提升精度
- 基于ImageNet预训练可以提升精度
- 训练时增强可以提升精度
- 把ResNeXt从101层提升到152层可以提升精度
- 测试时增强可以提升精度
YOLOv1
原理介绍
把目标检测当作一个回归问题求解,inference只需一次回归,用速度换精度。
yolov1把输入图像划分为S*S的格栅,每个格栅负责检测中心落在该格栅的目标,包括目标的坐标值(x, y, w, h)和confidence scores。另外,每个格栅预测一个类别概率值,输出一张类别概率图。
confidence = P(obj) * IoU(truth,pred)
上式中,当格栅中心点没有目标时P(obj)为0,此时confidence为0;否则为IOU的值。
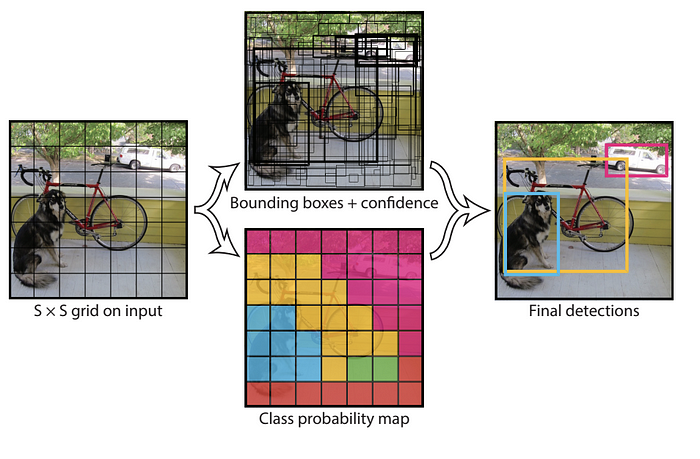
网络结构
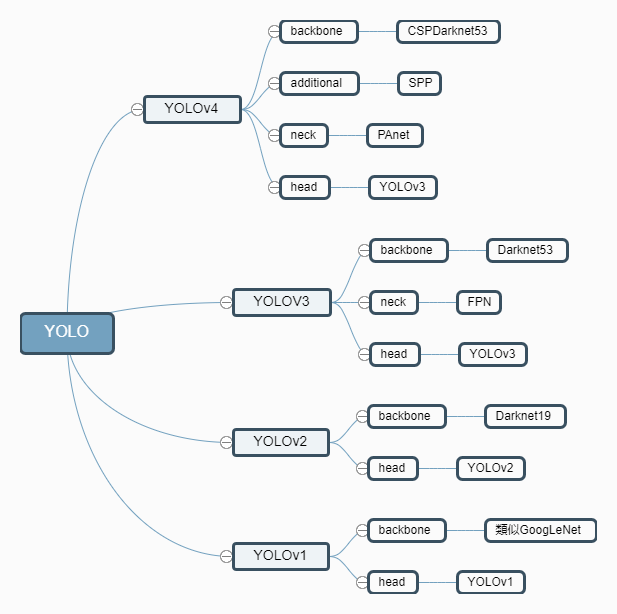
训练阶段
非线性激活函数:Leaky RELU
损失函数设计:损失函数设计的目标是将坐标 (x, y, w, h),confidence,classification这三个方面达到很好的平衡,所以不能简单的用平方根误差来对所有变量进行回归。
上图可见损失函数包含五项的和。
p1 ————第一项+第二项是坐标的偏移,赋予很高的loss权重,实验中取5。第一项是x和y坐标的偏移,第二项是w和h坐标的偏移。
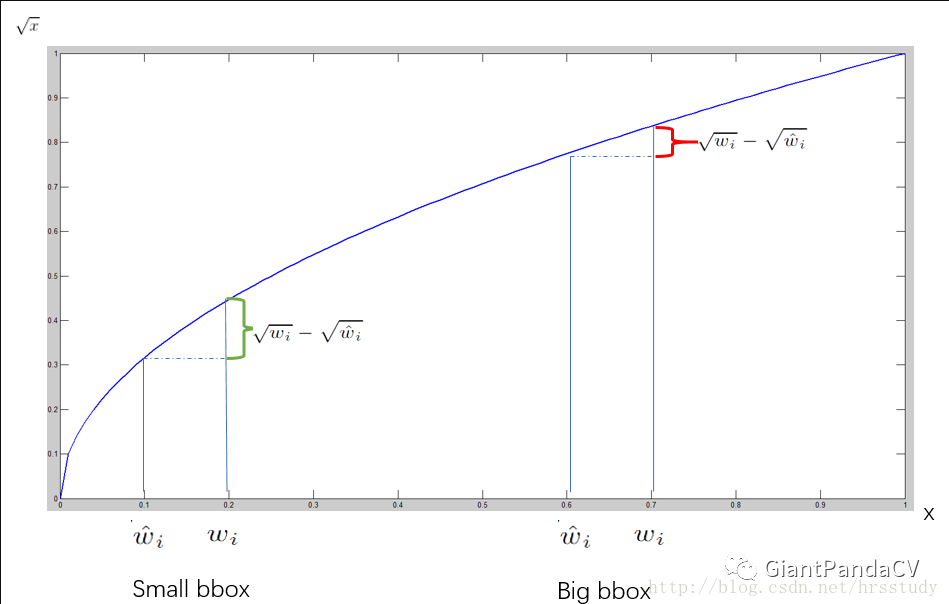
p2 ————针对第二项,作者用w和h的平方根偏差来计算loss是为了凸显小目标发生偏差的损失。
解释:在yolo的样本标签中,w和h是bbox相对图像的宽高大小,目标越大,w和h就越大,目标越小,w和h就越小。小的目标发生Δw和Δh的偏差反映在平方根上要大于大目标的值,以此来放大小目标的损失,来提升小目标的检测效果,具体原理见下图:
p3 ————第三项+第四项是bbox的confidence损失,但是分为含有object和不含object,不含object的confidence损失给了0.5的权重。我是这样理解的,不含object的bbox要比含有object的bbox多的多,为了防止其挟持梯度下降过程导致模型难收敛或发散而给予小的权重。
p4 ————第五项是类别图的损失,权重为1。
推理阶段 每个格栅包含SSB个bbox的预测,如果S=7 B=2,则每个格栅有98个bbox预测结果.
将bbox的IoU和格栅的类别概率相乘得到class-special confidence score,这个score衡量预测的精度.
1. 每个格栅的每个bbox都要计算class-special confidence score;
2. 按照score进行阈值过滤来剩下高分数的bbox;
3. 再进行NMS重叠过滤来输出最终的预测结果。
YOLOv2
提升:anchor boxes
相比yolov1划分SS大小的格栅,每个格栅预测B个目标,yolov2引入anchor boxes,在特征图的SS(13 * 13)的格栅上预测5个anchor boxes,对于每个anchor box预测bbox的的坐标、置信度和分类概率,可以预测13 * 13 * 5 = 845个bbox,大大提升模型召回率(漏检少了)。
同样是ancher-based的检测器,不同于faster rcnn在每个cell手动设置9个anchor boxes,yolov2的作者通过在COCO和VOC数据集上做kmeans聚类来确定anchor boxes的个数、分布和形态。如下图:
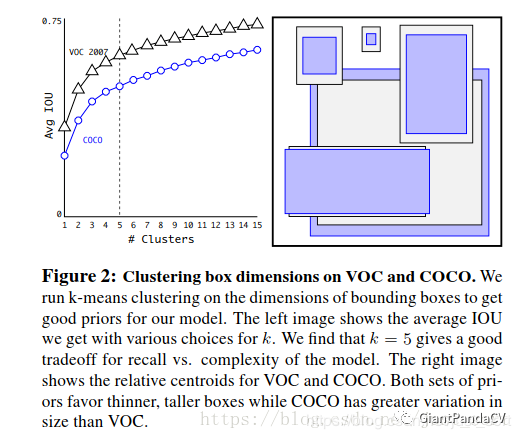
思考:对于我们的遥感数据集也按这样的方式设计anchor是不是可以提升检测效果?
路人甲:聚类完更差
路人乙:聚类了收敛比较快,性能提升一丢丢
提升:新的backbone
Darknet-19
提升:多尺度训练
不固定训练图像尺寸
提升:损失函数
沿用yolov1的训练方式,将损失分为坐标、IoU和类别概率三部分,但是做了不少改进,变得更复杂了。
YOLOv3
看下图就够了,相比v2也就增加了残差模型Darknet-53和FPN结构。
解释上图:
左侧是包含五个残差块的Darknet-53 backbone
右侧为FPN结构及在其上进行的三个anchor-base的检测路. FPN就是一种金字塔结构,在不同尺度上输出特征映射
yolov3在三个尺度上输出特征映射进行预测,算是多尺度预测,三个输出特征映射分别是(batch, 52, 52, 75), (batch, 26, 26, 75), (batch, 13, 13, 75)。每个预测尺度上基于维度聚类的方法在每个cell上生成3个anchor boxes,和faster rcnn一样总共也是9个anchor boxes。
yolov3-tiny是更加轻量级的yolov3,层数大大约减,但是依然保留了两个尺度的独立检测,输出分别为(, 13, 13, 255)和(, 26, 26, 255),网络结构见下图:
YOLOv4
特征提取更复杂了,数据扩充方法增加了不少,检测头没什么变化。
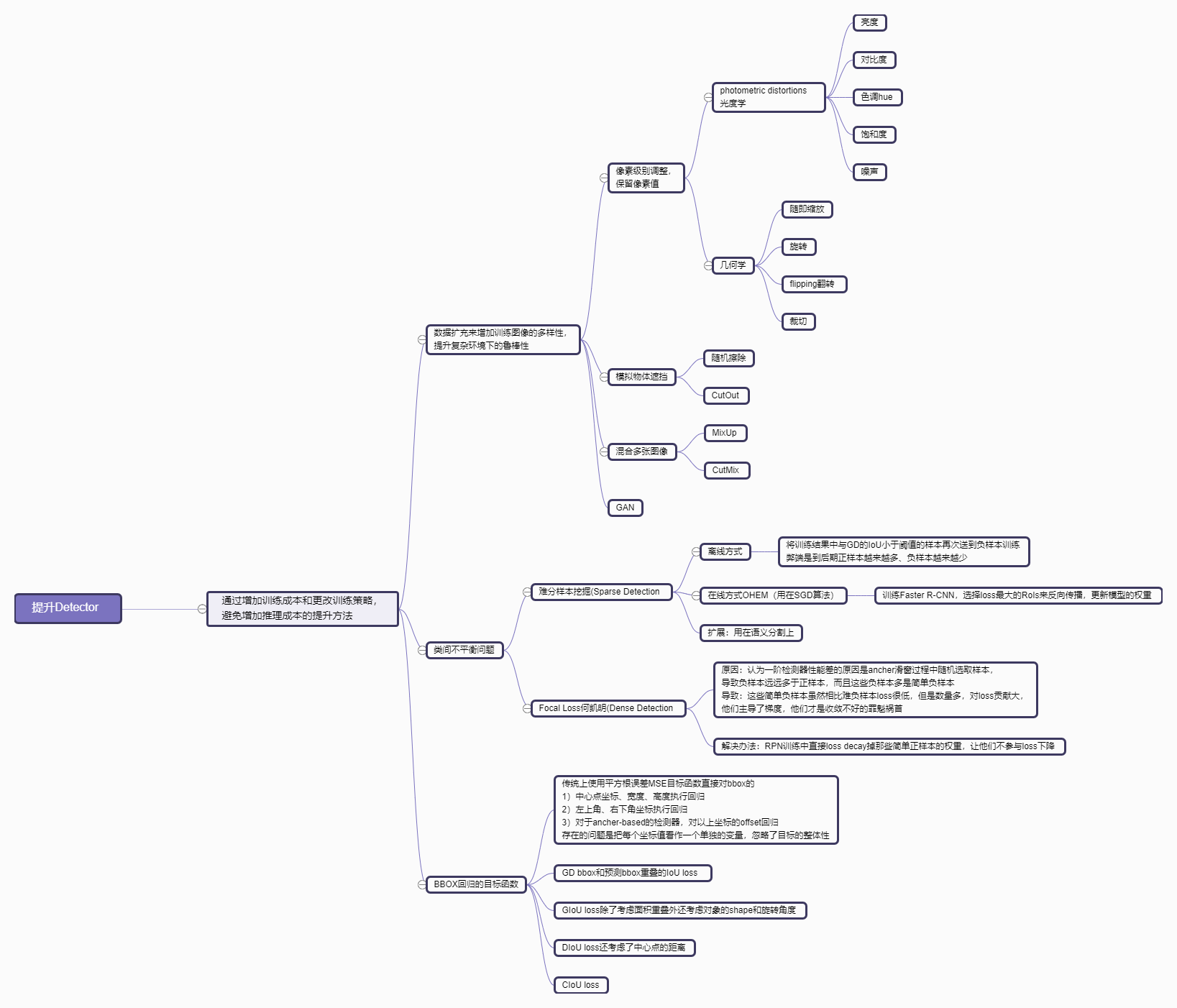
目标检测思维导图
目标检测网络一般结构:
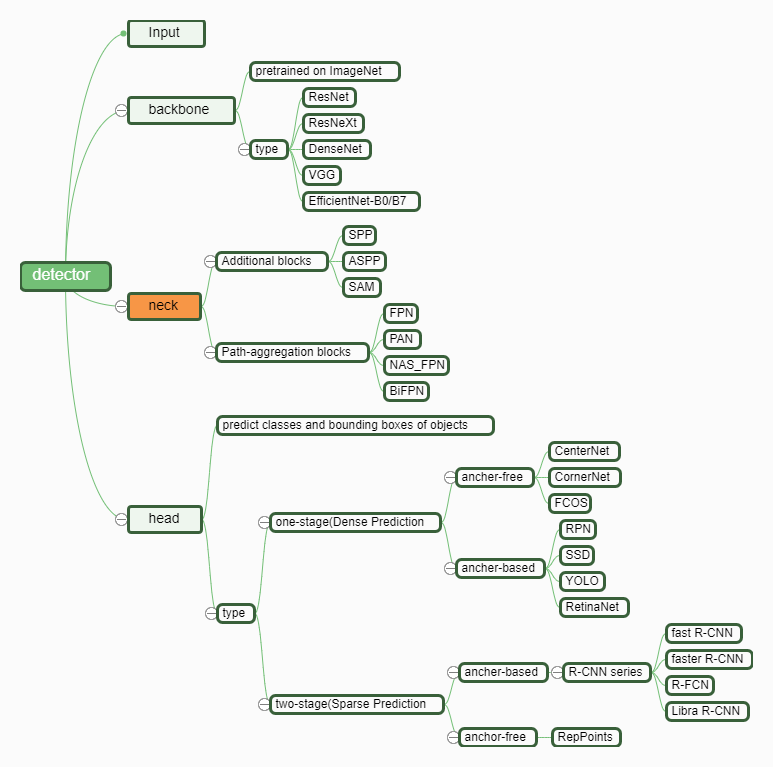
目标检测提升方法: